![]() MMEvalPro
MMEvalPro
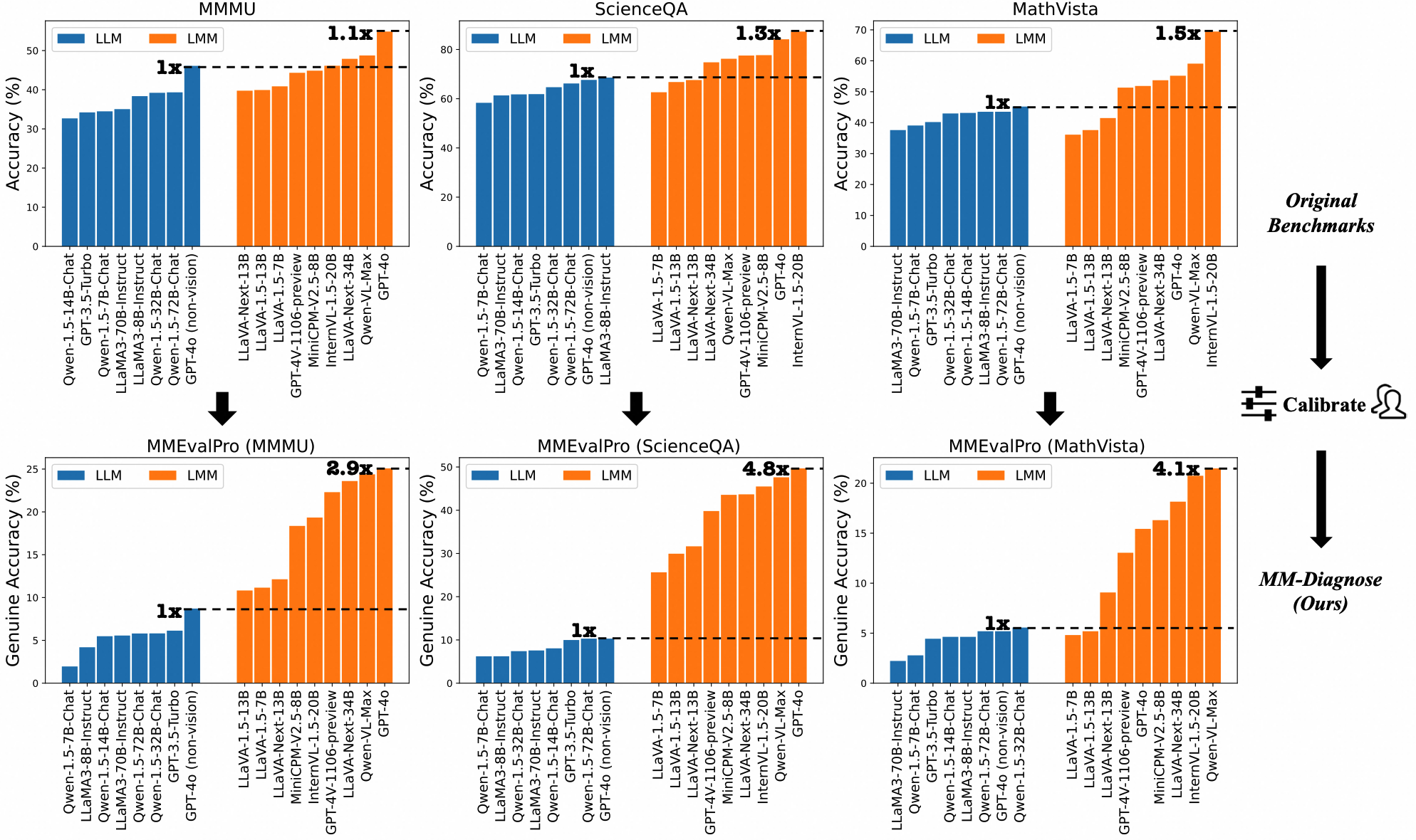
LLMs and LMMs' performance comparison between original multimodal benchmarks (MMMU, ScienceQA, MathVista) and MMEvalPro. Performance gap between LLM and LMM is much clearer in MMEvalPro.
![]() Leaderboard
Leaderboard
Rank |
Model |
Open? |
MMEvalPro | |||
|---|---|---|---|---|---|---|
| Average | MMMU | ScienceQA | MathVista | |||
| Genuine Accuracy / Average Accuracy | ||||||
| # | Human (Graduate Student) | - | 62.89% / 80.28% | 38.10% / 66.67% | 64.42% / 81.09% | 86.14% / 93.07% |
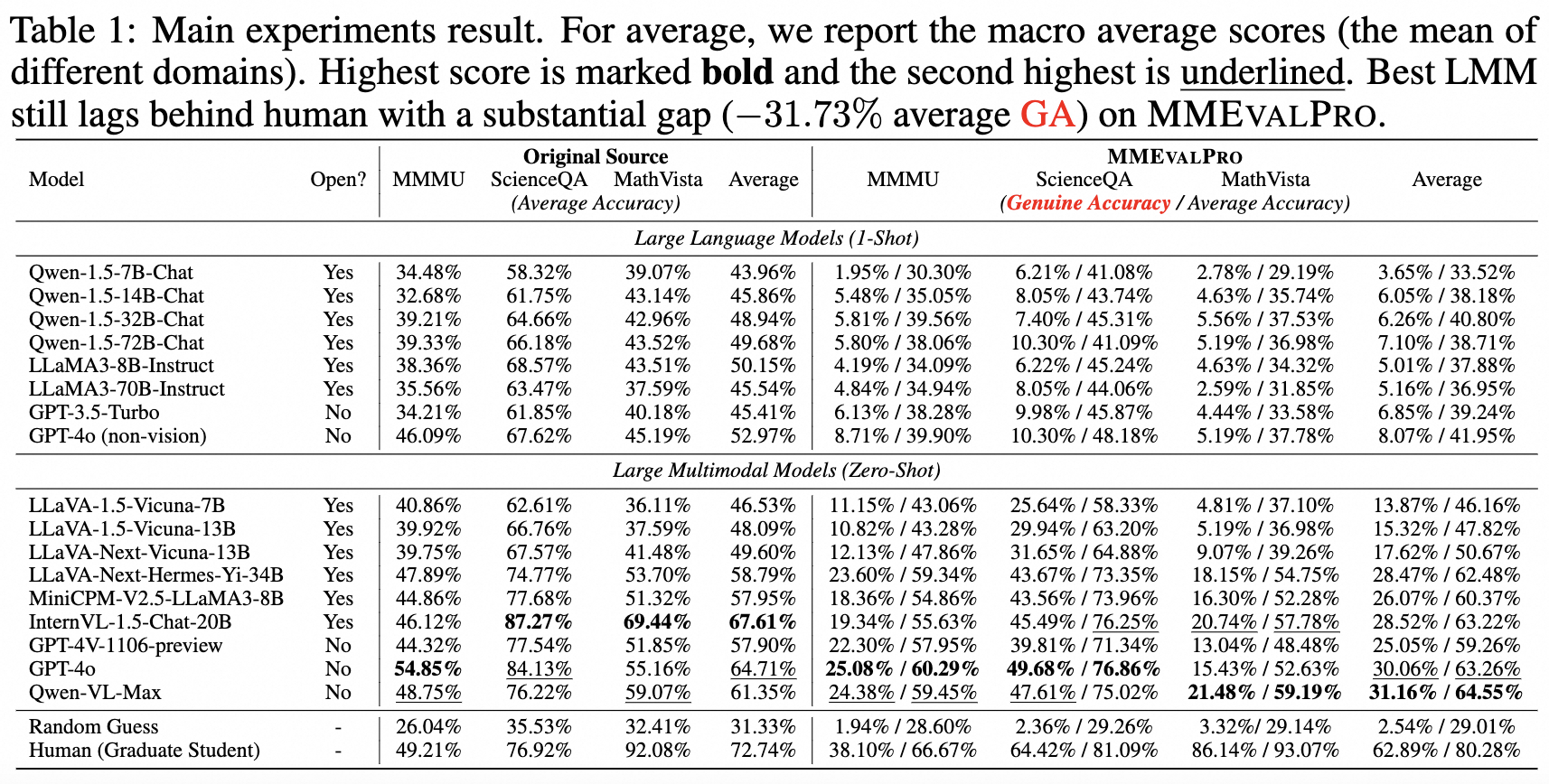
| 1 | Qwen-VL-Max | No | 31.16% / 64.55% | 24.38% / 59.45% | 47.61% / 75.02% | 21.48% / 59.19% |
| 2 | GPT-4o-0513 | No | 30.06% / 63.26% | 25.08% / 60.29% | 49.68% / 76.86% | 15.43% / 52.63% |
| 3 | InternVL-1.5-Chat-20B | Yes | 28.52% / 63.22% | 19.34% / 55.63% | 45.49% / 76.25% | 20.74% / 57.78% |
| 4 | LLaVA-Next-Hermes-Yi-34B | Yes | 28.47% / 62.48% | 23.60% / 59.34% | 43.67% / 73.35% | 18.15% / 54.75% |
| 5 | MiniCPM-V2.5-LLaMA3-8B | Yes | 26.07% / 60.37% | 18.36% / 54.86% | 43.56% / 73.96% | 16.30% / 52.28% |
| 6 | GPT-4V-1106-preview | No | 25.05% / 59.26% | 22.30% / 57.95% | 39.81% / 71.34% | 13.04% / 48.48% |
| 7 | LLaVA-Next-Vicuna-13B | Yes | 17.62% / 50.67% | 12.13% / 47.86% | 31.65% / 64.88% | 9.07% / 39.26% |
| 8 | LLaVA-1.5-Vicuna-13B | Yes | 15.32% / 47.82% | 10.82% / 43.28% | 29.94% / 63.20% | 5.19% / 36.98% |
| 9 | LLaVA-1.5-Vicuna-7B | Yes | 13.87% / 46.16% | 11.15% / 43.06% | 25.64% / 58.33% | 4.81% / 37.10% |
| 10 | GPT4o (no image) | No | 8.07% / 41.95% | 8.71% / 39.90% | 10.30% / 48.18% | 5.19% / 37.78% |
| # | Random Guess | - | 2.54% / 29.01% | 1.94% / 28.60% | 2.36% / 29.26% | 3.32% / 29.14% |
![]() What's the Problem of current LMM benchmarks?
What's the Problem of current LMM benchmarks?
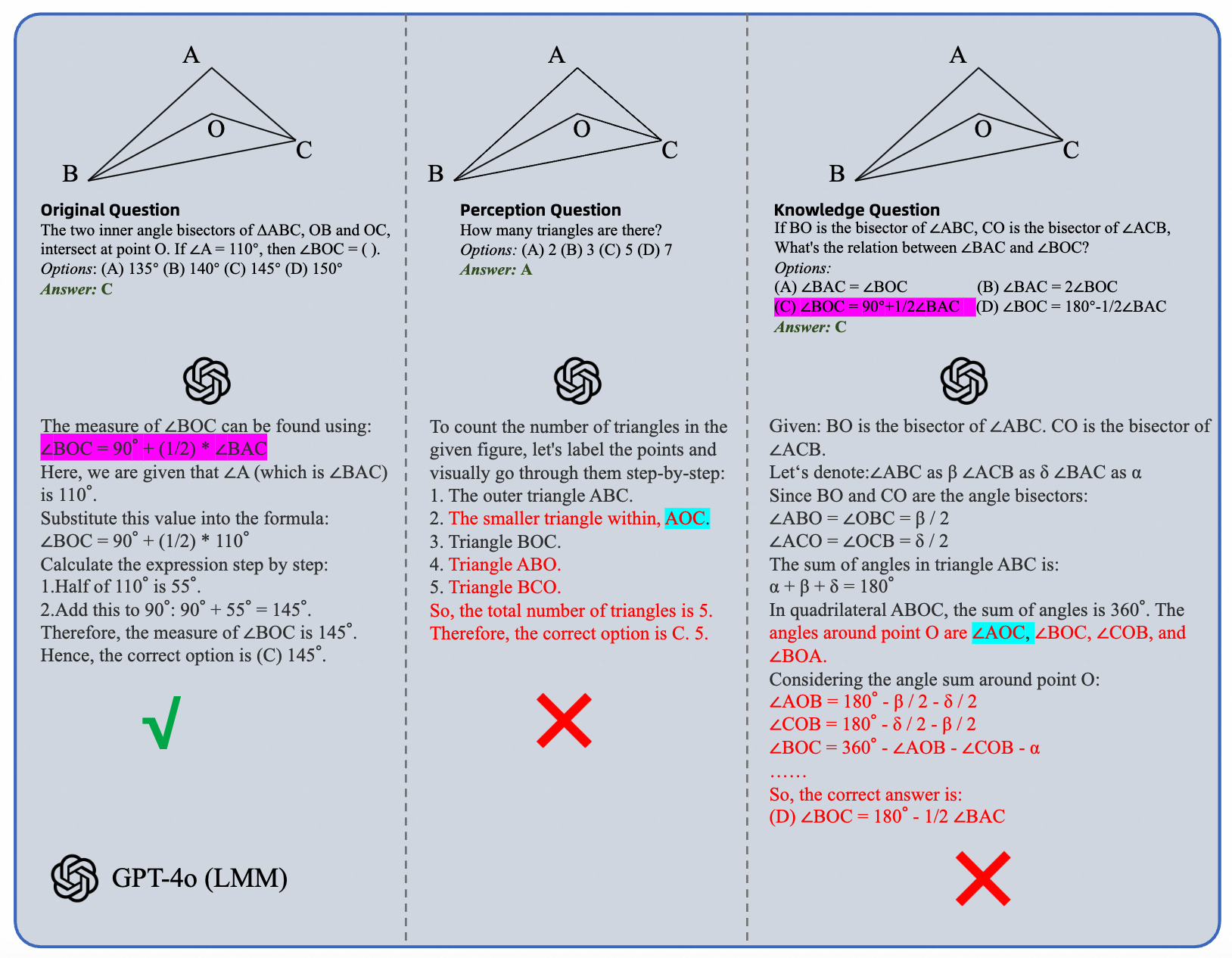
Our Answer Consistency Test into multiple choice questions (MCQ) reveals a prevalent Type-I Error in such evaluation's conclusion, where models could output correct answers without actual comprehension. For example as shown in the case below, the model could calculate the degree for a particular angle, but could not recognize the correct angle's name in the figure, which is a prerequisite to compute the degree. This phenomenon is common in existing benchmarks, leading to the overestimation of models' multimodal capabilities.
![]() Dataset Creation Process
Dataset Creation Process
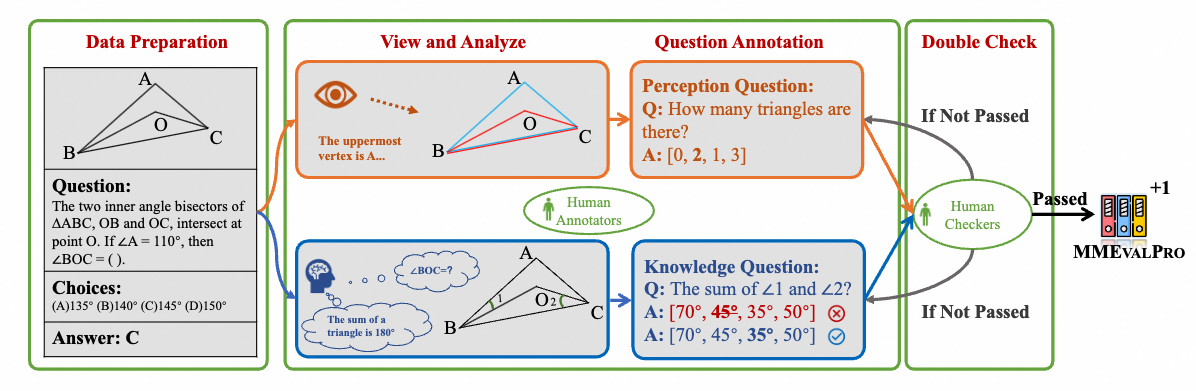
To this end, we propose MMEvalPro to truthfully reflect the true multimodal capabilities of tested models and keep the simplicity of MCQ evaluation. We achieve this by augmenting the original MCQ with perquisite perception and knowledge questions. We propose Genuine Accuracy as the main metric, which depends on whether the model answers the triplet questions concurrently.

Overview of our dataset curation process. We first collect questions from existing benchmarks and then manually augment them with perception and knowledge anchor questions. All questions are then labeled and double checked by human experts.
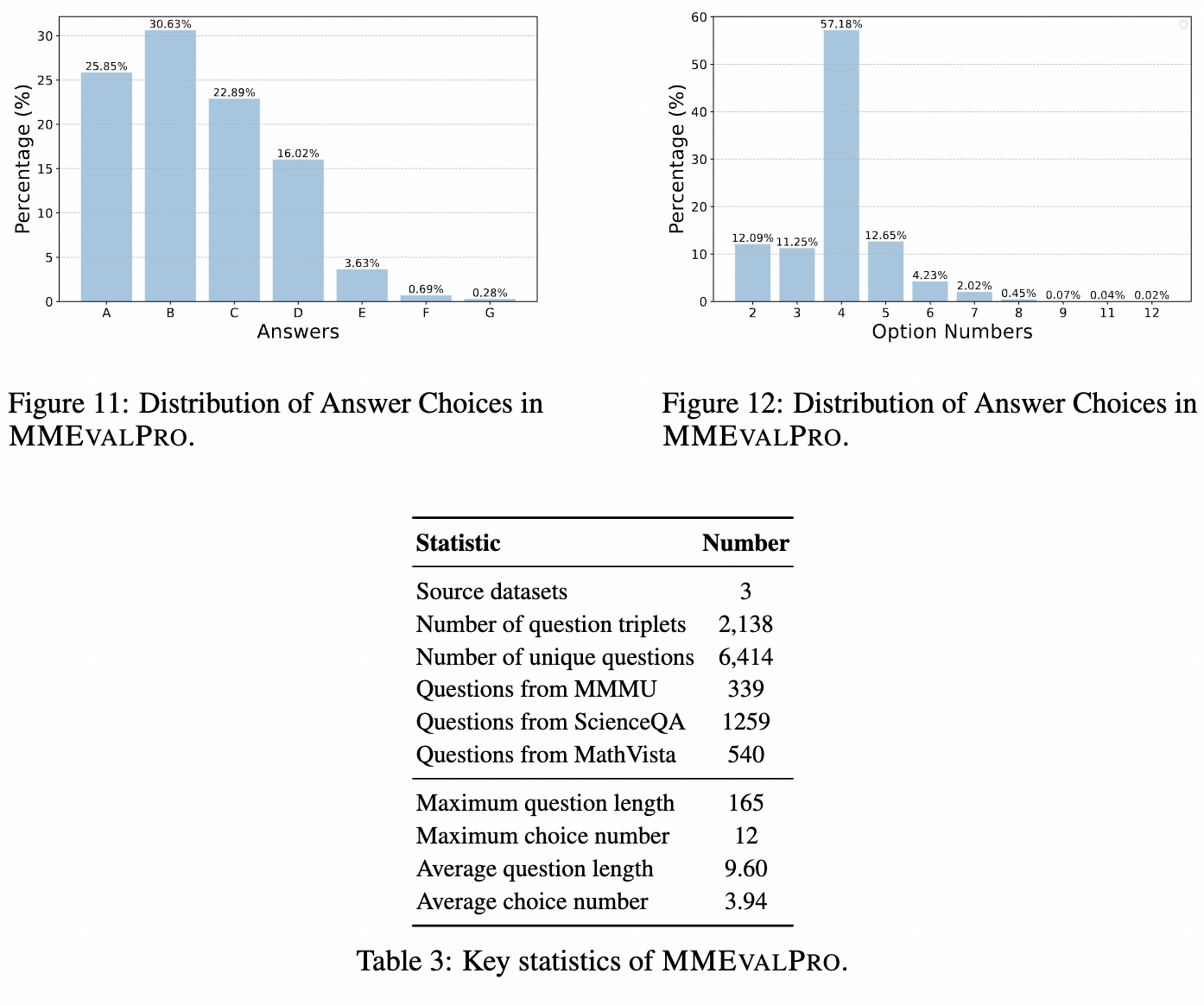
Some detailed statistics of our dataset are listed below.
![]() Evaluation
Evaluation
We evaluate the performance of the latest LLMs and LMMs on MMEvalPro and the existing benchmarks. The results show that MMEvalPro is more challenging and trustworthy than existing benchmarks. The best LMMs (QwenVL-MAX, GPT4o) lag behind human performance by over 30%, compared to an average gap of 8.03% in previous benchmarks. The best LLM trails the best LMM by 23.09%, whereas the gap for previous benchmarks is just 14.64%.
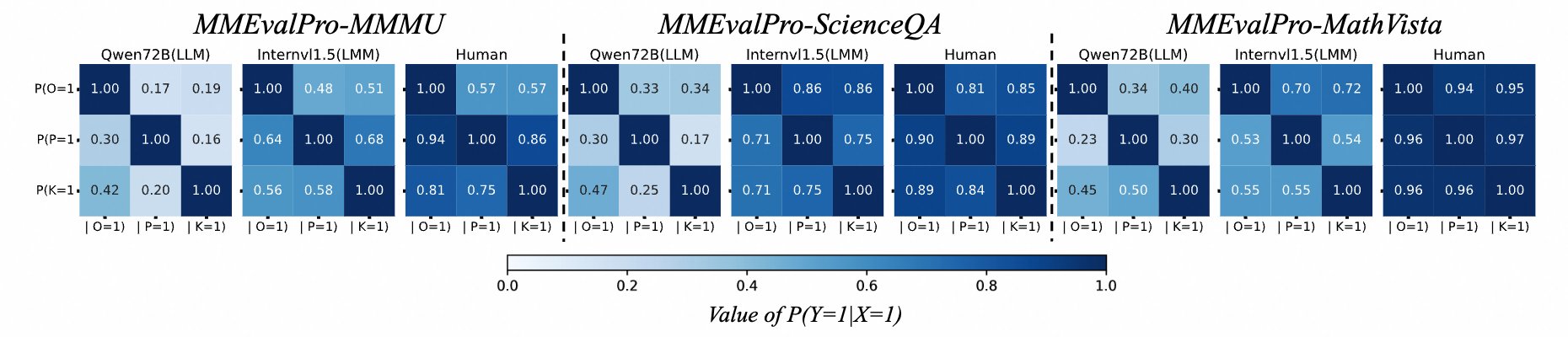
We further analysis what makes MMEvalPro difficult by visualizing all conditional probabilities (the answer consistency among two type of questions) for the best open-source LLM and LMM in the figure map below. Humans generally exhibit high probabilities of correctly answering one question given a correct answer to another, indicating consistent thinking. In contrast, LLMs show the lowest probabilities compared to LMMs and humans. This is expected, as LLMs lack consistent multimodal problem-solving paths due to their absence of visual perception, thus supporting the credibility of the benchmarks.
For more details, please refer to our paper, dataset and code, which are all available on the top of the page.
Acknowledgement
This website is adapted from ArxivCap, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.